
Let’s face it: As a marketer, have you ever launched a marketing campaign that received low engagement despite having the potential to drive high ROI for your brand?
We’ve all been in this situation.
The truth is, marketers and CMOs alike have no control over extrinsic influences on their campaigns such as an unanticipated market trend. The impact is often detrimental to destroy months of hard work your team has put in.
In marketing, we call these events “noise”. Marketers perform causal impact analysis to reduce the impact of noise to identify a campaign’s real statistical implications on an organization’s overall ROI. The actual results give them the confidence to move ahead or to pivot.
The mental model marketers use to analyze the causal impact of a campaign is called – the levels of evidence ladder.
In this article, we will explain the concept of causal impact analysis in marketing and the different methods that are part of the evidence ladder to make causal impact analysis a success.
What is Causal Inference in Marketing?
Causal inference in marketing tries to relate two or more variables in a way that we understand what one variable(s) caused in the other variable(s).
Judea Pearl mentions in her research paper that causal inferences go a step ahead of traditional statistical methods and capture the cause-and-effect relationship between the variables.
For example, how the financial crisis of 2008 (variable A) impacted Starbucks’ financial performance (variable B).
Marketers opt for an evidence ladder to measure the correlation between two or more variables. The evidence ladder includes different types of experiments to execute causal inference successfully.
The methods residing at the higher ends of the ladder make it difficult to set up experiments. However, they provide more concrete evidence to prove the relationship between the two variables. Alternatively, methods residing in the lower ends of the ladder are simpler to conduct but require in-depth analysis to identify significant insights.
An evidence ladder looks like this:
Evidence ladder Causal Inference 
The methods mentioned in the ladder are:
- Scientific experiments
- Statistical experiments
- Quasi-experiments
- Counterfactual experiments
Let’s deep dive into the methods of causal inference.
A/B Tests – The Gold Standard
A/B tests reside at the higher end of the evidence ladder and are also known as Randomized Control Trials. Any statistical experiment relies on randomness, and A/B tests signify that concept well which is why it is considered a “gold standard” when conducting causal inference.
Here, marketers randomly assign any groups as A and B and place both groups in the same environment with the exception of only one parameter – how the variables are treated. This way, identifying the causal impacts for both A and B becomes easier as the only difference between these groups is treatment.
Nevertheless, this is more of a textbook concept, and many other differences take place in a practical scenario.
Suppose a brand launches two Christmas campaigns – one in the USA and the other in Australia. The product, offers, and target audiences are similar; from the brand’s perspective, the only difference is the location. With A/B tests, the brand aims to identify how these two campaigns performed, their impacts on overall sales, and the upcoming strategies.
But in practice, there are some other major changes between the two locations that affect the A/B test results, such as – weather, currency, and buying pattern differences.
While A/B tests are popular, there are some limitations to this method when performing causal impact analysis:
- A/B tests are limited to a single variable – treatment. In a practical scenario, there will be a lot more potential influences that A/B tests don’t take into consideration.
- If you are starting A/B tests from scratch, there are additional set-ups like finding a tracking mechanism and analyzing all relevant metrics among others.
Quasi-Experiments – The Second Best Option
Performing A/B tests requires a certain set-up and efficient tools. Sometimes, marketers are unable to implement A/B tests because of ethical concerns. In those cases, the second best option to conduct causal impact analysis is – quasi-experiments.
A quasi-experiment is when control groups (A and B mentioned in the previous case) and treatment are not random (like explained in A/B testing). These two factors are close enough to estimate their correlation. In a practical scenario, this refers to having different assumptions about how close the two factors are concerning the A/B testing situation or a situation of randomness.
In simpler terms, quasi experiment is defined as an experiment to establish a cause-and-effect relationship between the independent and dependent variable.
The three types of quasi-experimental design
Linear regression with fixed effects/Non-equivalent groups design – Here the assumption is that you have collected datasets related to all factors that divide individuals between control groups and treatments. If this assumption is valid, you have an in-depth estimate of the causal effect of being part of the treatment.
Fixed effects and difference-in-differences/ Regression discontinuity – The marketer finds a control group showcasing a trend that is parallel to your treatment group before any treatment is applied. Once the treatment takes place, the second assumption is that the break in the parallel trend takes place due to the treatment.
Natural experiments – Here, an external event or situation results in random assignment of subjects to the treatment group. However natural experiments are not considered to be true experiments as they are observational in nature. That said, while you have no control over the independent variable, you can use these experiments to study the effect of the treatment.
Counterfactuals – When Experiments Aren’t an Option
The third method that doesn’t require you to perform any experiments is – counterfactuals. In this causal inference method, marketers rely solely on observational data to identify and deduce the causal impact on marketing initiatives.
But, by “observational data”, we don’t mean that you will observe a data pattern for a particular timeframe and perform a simple before vs. after analysis to identify the causal factors.
What we mean is you have to develop a model that monitors and computes counterfactual control groups. Here, “counterfactual” means what would happen if a particular feature didn’t exist in a product or a particular action was not taken in a marketing campaign.
The quality of forecasting plays a central role in counterfactuals. This model doesn’t go much into the technical details. It needs to be accurate and understand the factors responsible for driving an event in a certain way. If the confounding factor is independent of the latest event like weather changes or political turmoil, you don’t focus on that change. Your model should be trained to provide this evidence.
Let’s take an example of counterfactuals in marketing.
You launch a simple retention campaign to reduce the cart abandonment rate of your online store. You add an extra step to reclaiming abandoned carts. The goal is to notice if this step reduces customer retention rate or if customers overcome it to complete the purchase.
Accordingly, you train a model on datasets like the number of users returning to the ecommerce store to complete their checkouts for items left in abandoned carts and global trends of abandoned cart recovery for your store.
These variables were independent of the new step added to the retention campaign. Upon analysis, if the model shows a reduction in the abandoned cart recovery rate, it would mean that the extra step didn’t make any difference for the ecommerce shoppers.
The Role of Robustness in Causal Inference
While quasi-experiments and counterfactuals are great methods to analyze causal inference, one challenge exists. Since these methods don’t rely on randomness, the level of uncertainty is often high as it is harder to estimate sensible confidence intervals.
The best way to handle such situations is to focus on robustness.
“Robustness” is used to clearly explain all your assumptions, methods, and data and gradually slow them down to observe if the outcomes are still intact.
Robustness check is a quality check to ensure there are no drastic changes in your datasets due to one factor. This is even more relevant when causal inference is involved.
Marketers use Direct Acyclic Graphs (DAGs) to measure robustness.
Here’s an example of a DAG causal inference:
Example of a DAG causal inference 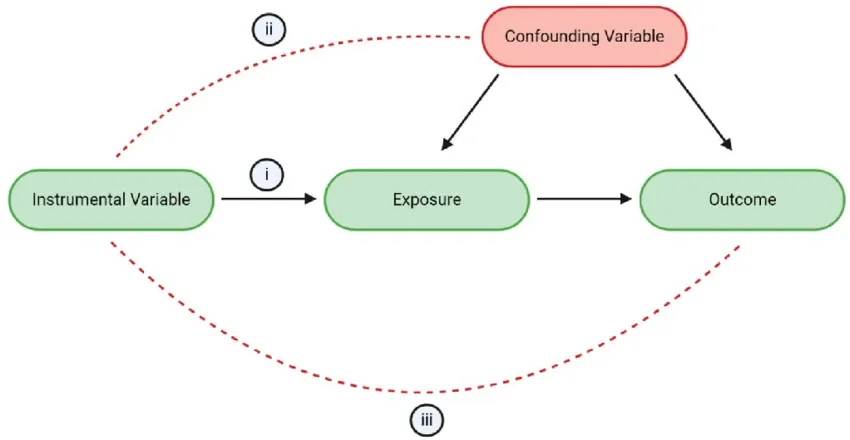
The above DAG shows the relationship between instrumental variables, confounding variables, exposure, and outcome. The black arrows represent the causal impact, and the red dotted lines represent the violation of assumptions.
DAGs help marketers to identify clear differences between assumptions and hypotheses to deduce causal inferences.
A Case Study of Microsoft Teams
Here is a case study published by Min Kang, a Data Scientist working at Microsoft, on measuring the causal impact of customers’ attributes on product retention.
Microsoft’s customer strategy for onboarding commercial users to the cloud involves four main steps:
- Migrating from on-premises to online document and email services.
- Developing cloud collaboration through email groups and document co-editing.
- Creating cloud communities to gather users who often work together
- Adopting Microsoft Teams as a platform for modern collaboration and teamwork.
Previous studies revealed a strong positive correlation between cloud community membership and retention on Teams. To understand the true impact of community membership, the researcher implemented causal inference approaches to validate the onboarding strategy and estimate the user-level causal effect of cloud communities on Microsoft Teams retention.
The study measured retention status as a binary variable at different checkpoints and as a continuous variable expressing the total number of days since the user’s first activity on the app, providing a holistic perspective of user retention.
Results show consistency across different test sets and sensitivity analysis revealed a larger impact of cloud community membership on retention in the case of stronger treatments.
This approach allows Microsoft 365 businesses to quantify the causal impact of pre-on-boarding behaviors on Teams’ app retention, confirming the marketing strategy’s rationale and providing a benchmark for assessing the success of future campaigns.
Conclusion
Causal inference in marketing differentiates the noise from a set of data and identifies the real impacts of a marketing initiative on the overall ROI of the organization.
A/B tests are one of the easiest ways to analyze causal inference and are purely based on randomness.
Nevertheless, A/B tests require rigorous set-up, and marketers sometimes don’t have access to the right tools to execute them.
That’s when they opt for two other methods – quasi-experiments (based on assumptions) and counterfactuals (based on observational data).
We recommend opting for a data-driven approach when deducing causal impacts. That’s precisely why we recommend Lifesight’s Incrementality Testing model.
Here’s why leading organizations use the gold standard of measurement to understand the incremental impact of their online and offline campaigns.
- Automated incremental lift tests validate multi-channel media impact leading to confident spending
- Validate performance and strategies using audience split tests and geo-experiments to prove the impact of your marketing strategies with confidence
- Automatically build actionable scenarios to plan your spend for different budgets and find the best path of action. Custom-build scenarios based on your budget and target KPIs, ROAS, CPA, and incremental revenue
If you’re looking to measure causal impact on marketing, book your Lifesight demo.
FAQs
What are the characteristics of a quasi-experiment?
While quasi-experiment aims at establishing cause and effect relationship between dependent and independent variables, there is a slight manipulation. The key feature of a quasi-experiment is it doesn’t rely on any random assignment. Quasi-experiment assigns subjects to groups, depending on non-random criteria.
What is an experiment design?
By organizing, conducting, and interpreting experiments efficiently, the experimental design ensures that as much helpful information as possible is obtained by performing several trials.
Quasi-experiment vs experimental – what is the main difference?
Experimental designs identify independent variables before the research is initiated, whereas quasi-experimental designs identify them after the analyzed data.
What is a quasi-experiment example?
An example of a quasi-experiment is – a SaaS company installs a new IT helpdesk system to decrease internal IT costs. The technology is implemented, and the internal IT costs are measured before and after installing it.
What do you mean by counterfactuals in causal inference?
The counterfactual model considers causal factors as those that are necessary to produce an outcome (for example – treatment success).
What do you mean by direct acyclic graphs (DAG)?
A direct acyclic graph (DAG) gives a visual representation of causal relationships among a set of variables.
You may also like



Essential resources for your success











